Caching in Python Applications
bhavaniravi
•May 1, 2024
(Source/Credits: https://dev.to/bhavaniravi/caching-in-python-2a2l)
Caching in Python Caching, is a concept that was gifted to software world from the...
title: Caching in Python Applications published: true tags: canonical_url: https://bhavaniravi.com/WIP_caching_in_python/
Caching in Python
Caching, is a concept that was gifted to software world from the hardware world. A cache is a temporary storage area that stores the used items for easy access. To put it in layman’s terms, it is the chair we all have.

This blog covers the basics of
- What are Caches?
- Caching Operations
- Cache Eviction Policies
- Implementation of Cache Eviction Policies
- Distributed Caching
- Caching In Python
Conventional Caches
In the world of computer science, Caches are the hardware components that store the result of computation for easy and fast access. The major factor that contributes to the speed is its memory size and its location. The memory size of the cache is way less than an RAM. This reduces the number of scans to retrieve data. Caches are located closer to the consumer (CPU) hence the less latency.
Caching Operations
There are two broad types of caches operation. Cache such as Browser caches, server caches, Proxy Caches, Hardware caches works under the principle of read and write caches.
When dealing with caches we always have a huge chunk of memory which is time consuming to read and write to, DB, hard disk, etc., Cache is a piece of software/hardware sitting on top of it making the job faster.
Read Cache
A read cache is a storage that stores the accessed items. Every time the client requests data from storage, the request hits the cache associated with the storage.
- If the requested data is available on the cache, then it is a cache hit.
- if not it is a Cache miss.
- Now when accessing a data from cache some other process changes the data at this point you need to reload the cache with the newly changed data this it is a Cache invalidation
Write Cache
Write caches as the name suggests enables fast writes. Imagine a write-heavy system and we all know that writing to a DB is costly. Caches come handy and handle the DB write load which is later updated to the DB in batches. It is important to notice that, the data between the DB and the cache should always be synchronized. There are 3 ways one can implement a write cache.
- Write Through
- Write Back
- Write Around
Write Through
The write to the DB happens through the cache. Every time a new data is written in the cache it gets updated in the DB.
Advantages - There won’t be a mismatch of data between the cache and the storage
Disadvantage - Both the cache and the storage needs to be updated creating an overhead instead of increasing the performance
Write Back
Write back is when the cache asynchronously updates the values to the DB at set intervals.
This method swaps the advantage and disadvantage of Write through. Though writing to a cache is faster of Data loss and inconsistency
Write Around
Write the data directly to the storage and load the cache only when the data is read.
Advantages
-
A cache is not overloaded with data that is not read immediately after a write
-
Reduces the latency of the write-through method
Disadvantages
- Reading recently written data will cause a cache miss and is not suitable for such use-cases.
Cache Eviction Policies
Caches make the reads and write fast. Then it would only make sense to read and write all data to and from caches instead of using DBs. But, remember the speed comes only because caches are small. Larger the cache, longer it will take to search through it.
So it is important that we optimize with space. Once a cache is full, We can make space for new data only by removing the ones are already in the cache. Again, it cannot be a guessing game, we need to maximize the utilization to optimize the output.
The algorithms used to arrive at a decision of which data needs to be discarded from a cache is a cache eviction policy
- LRU - Least Recently Used
- LFU - Least Frequently Used
- MRU - Most Recently Used
- FIFO - First In First Out
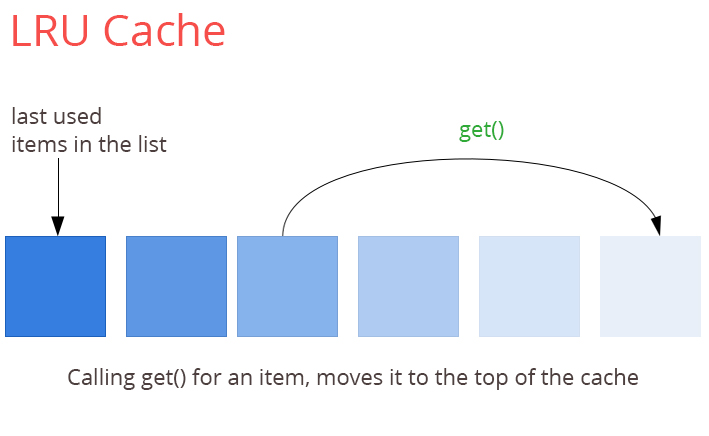
LRU - Least Recently Used
As the name suggest when a cache runs out of space remove the least recently used element. It is simple and easy to implement and sounds fair but for caching frequency of usage has more weight than when it was last accessed which brings us to the next algorithm.
LFU - Least Frequently Used
LFU takes both the age and frequency of data into account. But the problem here is frequently used data stagnates in the cache for a long time
MRU - Most Recently Used
Why on earth will someone use an MRU algorithm after talking about the frequency of usage? Won’t we always re-read the data we just read? Not necessarily. Imaging the image gallery app, the images of an album gets cached and loaded when you swipe right. What about going back to the previous photo? Yes, the probability of that happening is less.
FIFO - First In First Out
When caches start working like queues, you will have an FIFO cache. This fits well for cases involving pipelines of data sequentially read and processed.
LRU Implementation
Caches are basically a hash table. Every data that goes inside it is hashed and stored making it accessible at O(1).
Now how do we kick out the least recently used item, we by far only have a hash function and it’s data. We need to store the order of access in some fashion.
One thing we can do is have an array where we enter the element as and when it is accessed. But calculating frequency in this approach becomes an overkill. We can’t go for another Hash table it is not an access problem.
A doubly linked list might fit the purpose. Add an item to the linked list every time it is accessed and maintain it’s a reference in a hash table enabling us to access it at O(1).
When the element is already present, remove it from its current position and add it to the end of the linked list.
Where to Place the Caches?
The closer the caches are to its consumer faster it is. Which might implicitly mean to place caches along with the webserver in case of a web application. But there are a couple of problems
- When a server goes down, we lose all the data associated with the server’s cache
- When there is a need to increase the size of the cache it would invade the memory allocated for the server.
The most viable solution is to maintain a cache outside the server. Though it incorporates additional latency, it is worth for the reliability of caches.
Distributed Caching is the concept of hosting a cache outside the server and scaling it independently.
When to Implement Caches?
Finding the technologies to implement caches is the easiest of all steps. Caches promises high speed APIs and it might feel stupid not to incorporate them, but if you do it for wrong reasons, it just adds additional overhead to the system. So before implementing caches make sure
- The hit to your data store is high
- You have done everything you can to improve the speed at DB level.
- You have learnt and researched on various caching methodologies and systems and found what fits your purpose.
Implementation In Python
To understand caching we need to understand the data we are dealing with. For this example I am using a simple MongoDB Schema of User and Event collections.
We will have APIs to get User and Event by their associated IDs. The following code snippet comprise a helper function to get a respective document from MongoDB
def read_document(db, collection, _id):
collection = db[collection]
return collection.find_one({"_id": _id})
Python inbuilt LRU-Caching
``` from flask import jsonify from functools import lru_cache
@app.route(“/user/
try:
return jsonify(read_user(db, uid))
except KeyError as e:
return jsonify({”Status": “Error”, “message”: str(e)})
```
LRU-Caching like you see in the following example is easy to implement since it has out of the box Python support. But there are some disadvantages
- It is simple that it can’t be extended for advanced functionalities
- Supports only one type of caching algorithm
- LRU-Caching is a classic example of server side caching, hence there is a possibility of memory overload in server.
- Cache timeout is not implicit, invalidate it manually
Caching In Python Flask
To support other caches like redis or memcache, Flask-Cache provides out of the box support.
``` config = {’CACHE_TYPE’: ‘redis’} # or memcache app = Flask( name ) app.config.from_mapping(config) cache = Cache(app)
@app.route(“/user/
With that, We have covered what caches are, when to use one and how to implement it in Python Flask.
Comments section
valiahavryliuk
•May 1, 2024
Good post! Also, here is one more useful article about cache in asynchronous Python applications: medium.com/the-pandadoc-tech-blog/...
aminmansuri
•May 1, 2024
For cache eviction policies its also good to consider random eviction policies. Some of these can outperform deterministic policies like LRU.
An intuition as to why that is true is suppose you are sequentially reading data (a common use case) over and over again. If you have, say, 1000 items to read but your cache is of size 999 you will always get a cache miss because the next item you need will always be evicted. But if you chose a random eviction policy (there are several schemes) your cache misses would radically reduce.
If you're concerned about accidentally removing the most recent items (less probable as the cache gets bigger) then you can only evict things that are of a certain age (for example >5 mins).
We often don't experiment much with cache eviction but I could suppose that it wouldn't be hard to automate a cache eviction optimization policy: one where you automatically try different things and see which one minimizes cache misses per hour or something like that.