Usando Scrapy para obter metadados das músicas dos Parcels através do Genius
fannyvieira
•May 1, 2024
(Source/Credits: https://dev.to/opendevufcg/usando-scrapy-para-obter-metadados-das-musicas-dos-parcels-atraves-do-genius-1dhj)
Uso de webcrawler para extração de metadados de músicas
title: Usando Scrapy para obter metadados das músicas dos Parcels através do Genius published: true description: Uso de webcrawler para extração de metadados de músicas tags: crawling, music, ptbr, scrapy
Você já quis obter dados de um serviço que não disponibiliza uma API? Se você faz Computação na UFCG, provavelmente já escutou alguém falando do bot de matrícula. Já perguntou como ele funciona? Pois bem, no post de hoje você aprenderá como é possível fazer essas coisinhas e poderá usar sua criatividade para brincar e explorar ainda mais.
Mr. Robot

Um web crawler pode ser definido como um script ou programa que é utilizado para acessar um website, extrair conteúdo e descobrir páginas relacionadas ao mesmo, repetindo o processo até que não existam mais páginas a ser pesquisadas. Eles são muito importantes, pois as engines de busca os utilizam para retornar resultados eficientes; devido a isso, frequentemente, algumas pessoas se referem a eles como bots da internet. De uma forma superficial, você pode pensar no crawler como um carinha que faz requisições para as páginas que ele encontra e, à medida que percorre essas páginas, faz o parse do seu HTML.
Pré-Requisitos
Para conseguir reproduzir o que faremos nesse tutorial você precisará ter o Python 3 configurado. Uma alternativa é usar o virtualenv, que possibilita a criação de um ambiente de desenvolvimento isolado.
Além do Python 3, faremos uso do Scrapy, um framework que possui as ferramentas necessárias para extrair dados de websites, processar os que você queira e armazená-los na estrutura de seu interesse. Apesar de ser possível construir um crawler usando módulos fornecidos pelo próprio Python, à medida que o seu projeto cresce, pode se tornar complicado gerenciar a execução do seu robôzinho, por isso faremos uso desse framework. Entretanto, caso você tenha interesse em conhecer outras alternativas, deixarei links nas referências.
Para instalá-lo, utilize o índice de pacotes do Python(PyPI), através do seguinte comando:
pip install Scrapy
Feito isso, podemos dar início à nossa implementação.
Além das letras
Se você usa o Spotify, já viu que vez ou outra em algumas músicas são exibidas as letras e algumas informações interessantes que são extraídas do Genius. Motivada em obter essas informações de uma banda que eu conheci recentemente, chamada Parcels (inclusive, fica aqui a sugestão: se você gosta de Daft Punk, provavelmente vai curtir a música deles), decidi construir esse crawler.

A primeira coisa que um crawler precisa é de um ponto inicial, também chamado de seed, que será usado para iniciar a extração dos conteúdos. No nosso caso, esse ponto será a página da banda no Genius (essa aqui).
Uma vez que temos isso, podemos iniciar a construção do nosso robôzinho. Crie um arquivo python chamado genius.py, que possui o seguinte conteúdo:
```python import scrapy
class GeniusSpider(scrapy.Spider): name = "genius" start_urls = ['https://genius.com/artists/Parcels']
```
Primeiro, importamos o Scrapy para ter acesso às funcionalidades que esse módulo fornece. Em seguida, criamos um classe chamada GeniusSpider, baseada na Spider do Scrapy; é ela que define quais métodos estamos hábeis a usar, métodos estes que poderão nos auxiliar durante a execução do crawler. Por fim, definimos o nome do spider como genius e o nosso seed como sendo a página dos Parcels.
Diferentemente do que fazemos para executar scripts em Python, usaremos o comando que o próprio Scrapy provê por meio da sua CLI:
scrapy runspider genius

Certo, temos várias letrinhas bonitinhas e outras nem tanto, mas o que tudo isso quer dizer?
- O Scrapy carregou e configurou o que precisava para iniciar;
- Requisitou a url que definimos no
start_urls, e baixou o seu conteúdo; - Repassou esse conteúdo para um método parse. Como não o tínhamos criado, nada aconteceu e ele finalizou a execução.
Extraindo metadados
O próximo passo é definir como o Scrapy deve extrair o conteúdo: fazemos isso definindo o método parse. Nesse passo, é importante que você entenda como estão organizados os elementos da sua página, pois será essencial para transmitir ao crawler quais locais ele deve raspar quando extrair a página.

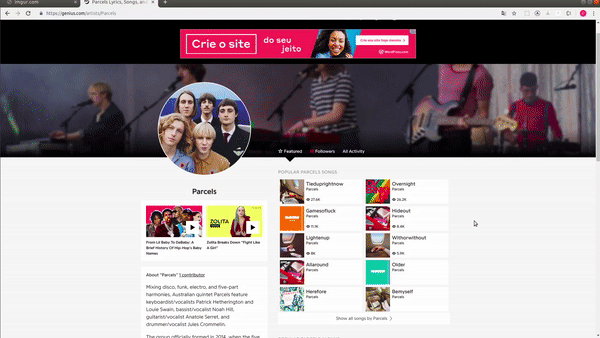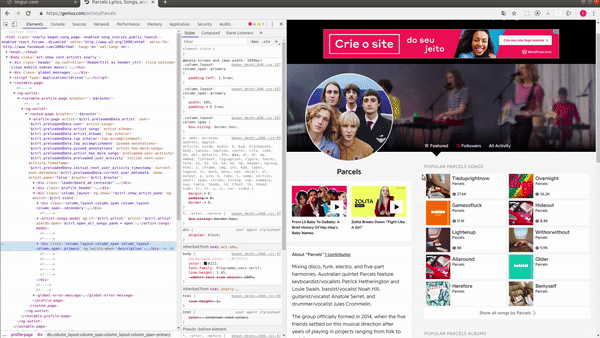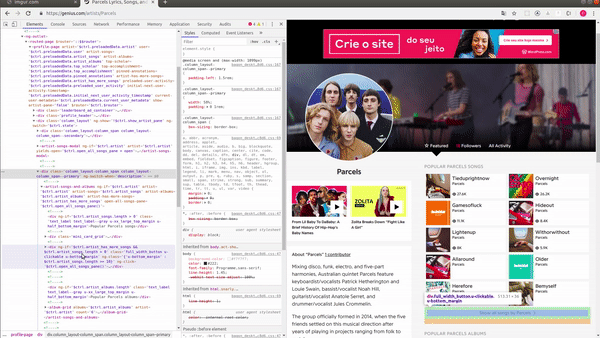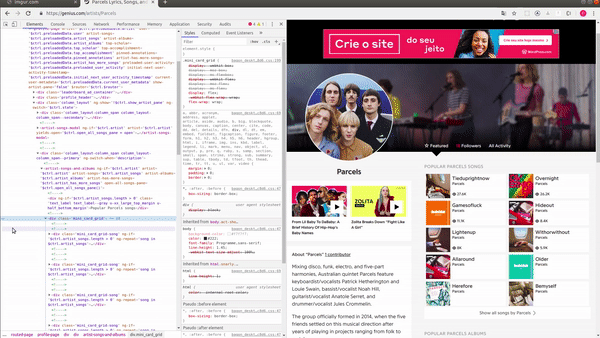
Analisando a imagem acima, você pode ver que à sua direita existe uma listagem de cards com as músicas populares que, quando clicados, nos levam ao conteúdo que queremos. Dessa forma, esse deve ser o local de onde nosso crawler irá extrair os links.
O Scrapy extrai o conteúdo através de seletores, que são "padrões" ou "modelos" que casam com os elementos de uma árvore do documento e portanto podem ser usados para selecionar os nós de um documento HTML. Para conseguir fazer isso, o Scrapy fornece duas formas: através do Xpath e através de seletores CSS; usaremos os seletores CSS por questão de simplicidade.
Usando o inspetor do meu browser para analisar quais os nós que contêm esse link e então formar o nosso seletor, consegui notar que o elemento que contém essa lista de cards é uma div. Veja no GIF:
```html
```
Sendo assim, podemos informar ao Scrapy que ele deve obter algo como:
div.mini_clard_grid-song a::attr(href)
Isso indica que queremos os links que são filhos de um elemento da classe mini_card_grid-song, por isso o . (como em CSS). Além disso, adicionamos esse trecho ::attr(href) depois da tag a, porque se definíssemos o padrão apenas com a tag teríamos todo o nó HTML, e não apenas a url.
Para entender melhor sobre os seletores CSS, veja esse link da documentação.
Assim, podemos construir nosso método:
python
def parse(self, response):
songs_urls = response.css('div.mini_card_grid-song a::attr(href)').getall()
for song_url in songs_urls:
yield scrapy.Request(url=song_url, callback=self.parse_lyrics_page)
O método é composto por um parâmetro response, que indica o conteúdo obtido após o crawler ter requisitado nossa url inicial. Feito isso, temos as urls das músicas sendo obtidas a partir do nosso seletor; essa lista de urls que o crawler requisitará é chamada de frontier. É importante ressaltar que usamos o getAll(), porque queremos extrair todos os seletores que casarem com o padrão que passamos, mas às vezes estamos interessados apenas na primeira ocorrência e podemos fazer uso do get(). Uma vez que temos as urls, fazemos as requisições, passando a url e uma callback, que é uma função que será executada após o crawler fazer download da url que passamos.
Ótimo, conseguimos alcançar as páginas das nossas músicas, mas depois que chegamos nelas, o que faremos? Seguimos um processo muito parecido com o anterior, diferindo apenas que, ao invés de tentar extrair links, poderemos extrair as informações desejadas. Do passo anterior, vemos que o método que será executado após ser consultada a página da música é o parse_lyrics_page, então adicione esse trecho ao seu arquivo:
```python
def parse_lyrics_page(self, response):
title = response.css('div.song_body-lyrics h2::text').get()
song_metadata = response.css('div.rich_text_formatting p::text').getall()
artists = set(response.css('span.metadata_unit-info a::text').getall())
lyric = response.css('div.lyrics p::text').getall()
annotations_ids = response.css('a::attr(annotation-fragment)').getall()
item = {
'title': title,
'artists': artists,
'lyric': lyric,
'metadata': song_metadata,
'snippet_lyric': [],
'annotations': []
}
if annotations_ids:
return self.get_annotations(response, annotations_ids, item)
else:
return item
def get_annotations(self, response, annotations_ids, item):
for annotation_id in annotations_ids:
url = urljoin(response.url, annotation_id)
yield scrapy.Request(
url=url,
callback=self.parse_annotation_page,
meta={'item': item}
) ```
Muita coisa, né? Mas vamos por partes, como diria Jack.
Para extração das informações básicas como os artistas, a letra, o título e os metadados, não temos nenhuma novidade em relação ao que fizemos na extração dos links, já que só precisamos fornecer o seletor e ele irá obter a informação.
No entanto, as anotações seguem um comportamento diferente. Olhando a página, você verá que os elementos que deveriam conter as informações de anotações das músicas contém apenas um identificador, que redireciona para outra página que abriga o conteúdo delas. Então, o que estamos fazendo é:
Se existem anotações, obtenha seus ids e, para cada id obtido, concatene a nossa url inicial:
urljoin(response.url, annotation_id)
E, em seguida, fazemos uma requisição para cada um deles. Mas espere, essa requisição tem algo que ainda não vimos antes: um parâmetro chamado meta.

O meta é a forma que o Scrapy provê para que consigamos nos comunicar entre uma página e outra. Então, o que estamos querendo dizer é que toda vez que ele consultar as páginas das anotações, leve consigo as informações que já extraímos dessa. Isso será útil para unirmos os dois objetos e retornamos os resultados.
Agora que você está na página de anotações, encontre os seletores das anotações e retorne o resultado, e pronto, você terá feito o crawler. Deve ficar algo como mostrado no trecho abaixo:
```python def parse_annotation_page(self, response): snippet_lyric = response.css("meta[property='og:title']::attr(content)").getall() annotations = response.css("meta[property='og:description']::attr(content)").getall() item = response.meta['item'] item['snippet_lyric'] = snippet_lyric item['annotations']= annotations
return item
```
Caso não existam anotações, ele já retornará o resultado, que é o objeto com as informações que obtivemos na primeira página. Para salvar o que coletamos em um json, usamos o comando:
scrapy runspider genius -o parcels-lyrics.json
Você terá algo com: {% gist https://gist.github.com/fanny/06aaad556fcba66abbfba4dd22e18f3c file=parcels-lyrics.json %}
Nota: É possível salvar o dado em outros formatos, como csv, dê uma olhada na documentação.
E é isso, você construiu o crawler! :hoo-ray:

Considerações finais
Até aqui você aprendeu os conceitos básicos para construir um crawler. À medida que seu projeto expandir, você precisará lidar com outras coisas, como politeness policies, porque pense: se fizermos muitas requisições para um site, podemos sobrecarregá-lo e torná-lo indisponível por algum tempo para outros usuários. Leitura de sitemaps também são importantes para garantir que o crawler consiga obter efetivamente certos links que o website acredita ser essenciais, além de várias outras técnicas.
Entretanto, agora que você já sabe o básico, me conta nos comentários alguma ideia que você pensa em construir! E se tiver qualquer dúvida ou sugestão, fique à vontade para adicionar comentários neste post ou trocar uma ideia comigo fora dele (minhas redes sociais estão mapeadas no meu perfil).
E se quiser estar por dentro do que eu tô fazendo e escutando (música é realmente uma das minhas paixões além de Computação), me segue no Spotify ou Last.fm e GitHub.
Referências
Tutoriais
- Documentacão do Scrapy;
- Fazendo web crawlers em Python - Inglês;
- Utilizando o Scrapy do Python para monitoramento em sites de notícias - PTBR.
Livros
Obrigada
Muito obrigada pela leitura! Fique atento: em breve, teremos novos artigos de contribuidores do OpenDevUFCG aqui no dev.to. Acompanhe o OpenDevUFCG no Twitter, no Instagram e, claro, no GitHub.
Comments section
davidedup
•May 1, 2024
Não sei se fiz algo errado, mas quando fui rodas o script tive que fazer:
"scrapy runspider genius.py -o parcels-lyrics.json"
Quando tentei o comando:
"scrapy crawl genius -o parcels-lyrics.json"
Disse que o scrapy nao tem a função crawl
fannyvieira Author
•May 1, 2024
Oi @davidedup , você tem razão, o comando
crawlnão vai funcionar, porque ocrawlexecuta através do nome definido em um arquivosettingsque faz parte da configuração, via projeto do scrapy, enquanto orunspidernecessita apenas de um arquivo python para sua execução.Obrigada pela observação, editei o post, se você quiser ver funcionando usando esse outro comando, o projeto completo se encontra no meu github
davidedup
•May 1, 2024
topppp!!!! muito bom! eu amei!
s2s2s2
joseims
•May 1, 2024
Fanny você é incrível
lukehxh
•May 1, 2024
Post incrível e muito bem feito! <3